
Day 3 - Cleanup & Identify Visitor Source

I was reading up on using Lambda, Node and DynamoDB and found some samples with much cleaner/easier code.
So first I will clean up some of my the code from Day 1 and Day 2.
🔗Goodbye Express, Serverless-HTTP
The next part is blatantly stolen from the post below. If you need to know why please read the post below. All credits to Van Huynh
Create a file called src/utils/request.util.js for our request utility.
For now, the request utility will contain a single function that will accept some parser function and return a new function that uses it to parse some text we pass to it.
Create another file called src/utils/response.util.js for our response utility.
The withStatusCode response utility function is similar to the request utility, but instead of parsing text, it will format data into text. It also contains addition checks to make sure our status codes are within the range of allowable status codes.
Then we’re creating a factory as we keep instantiating DynamoDb with the same options:
Using those new utils our index.js looks like this
That’s right. No more express, body-parser or serverless-http. So remove them and make sure to uninstall
🔗More cleanup
I had some inconsistencies in serverless.yml. Using trackinstead of page for table names. Fix that in serverless.yml
Quick sls deploy to get everything deployed. We did rename a table so the page events will be empty 🤨
Allright. Ready to do some new stuff. 😎
So what we want to do is two things today:
- Store the identify() calls together with anonymousId so we can map visitor sessions (pages, tracks, …) to real users
- Run page() calls through some external library and detect what type of traffic it is (search, paid, social,…)
Streaming DB inserts🔗
Because I have my own dataset with historic segment events I think I might import the old historic archive later. For that reason, I have decided to use streaming to launch a 2nd Lambda function after the record is inserted. This way I can safely batch import old page events and know they will be handled by the same processing logic.
Let’s register two new functions and set up the streaming link in serverless.yml
Hit sls deploy
In some cases, I had to erase my deployment sls remove or even sls remove -f because some changes to the tables (setting up the streaming) could not be completed.
Don’t forget to export BASE_DOMAIN after that to point to the new deployment.
🔗Processing Identify calls
Every time an identify is stored (Day 2) another Lambda function is automatically called. Let’s add the code (in /processIdentify.js) to store a mapping (userId to anonymously)
Two new files come with that too. The first one is a model to keep our Lambda handler clean and DRY.
The second file is to deal with the fact that DB events come with a special (marshalled) format. As we need the original event we need to unmarshall it. Read about it at Stack Overflow.
After that deploy that function only.
sls deploy --function=processIdentify
Now try to hit your segment endpoint with a new identify event
http POST $BASE_DOMAIN/events < events/identify.json
In a new tab monitor the output
sls logs --function=processIdentify
After that, you will see that a new record was written to the user mapping table. Mine (with the example event) looked like this:
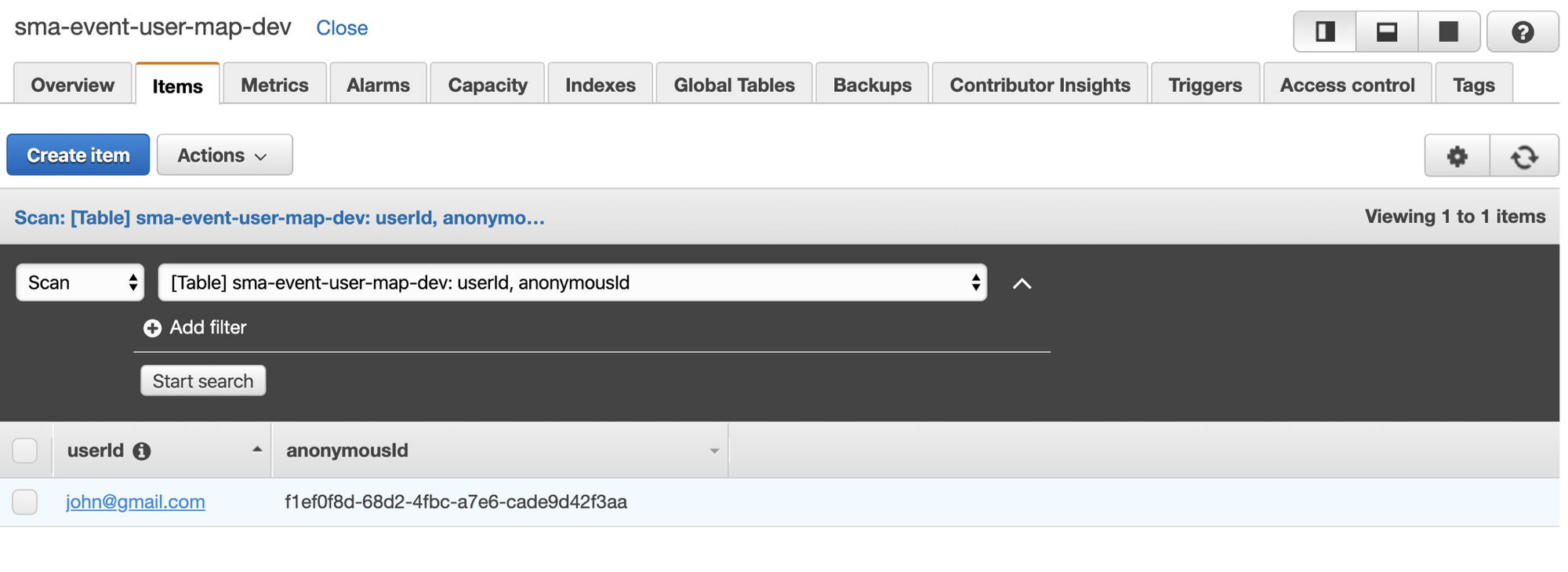
🔗Processing Track calls
Next up is processing track calls very similarly. We already have the DB and streaming function created.
As mentioned in the plan I wanted to use a library to parse the HTTP Referrer and current URL and group sessions in some kind of grouping (paid, social, referrer, search…).
A quick check those libraries I found segment/inbound the easiest library. But when using it I bumped on to some issues:
- Not maintained
- Does not detect referrer: https://www.google.com as search
- Outdated social networks and search engines
- Tests were broken
- Problem with a sublibrary that was accessing an external URL.
I found a better fork (better maintenance), but then I had to fork that again to apply some of my own fixes. Too bad I didn’t know about Monkey Referrer then :-( For now we’ll use the fork I created.
I need two new utils to keep the function clean:
The first is using this inbound library and returning a promise to parse the HTTP referrer and/or current URL and return something useful.
Another one to extract the important properties from a page() event
Making the processPage file (also automatically called on DB inserts) look like this
In short this will:
Get the page() payload -> run it through inbound lib -> store that together with url and HTTP referrer in a new table optimised for reads by anonymousId.
One more file (the model)
Give it a quick deploy
And after feeding the test event (make sure to clear the page table first) you should see some events.
So this call feeds the webhook (created in Day 2) a new page() event just like segment would. After that insert, DynamoDB is automatically calling another Lambda function (processPage) that runs the HTTP referrer and current URL through the inbound library and storing that payload (together with other important properties) in sma-event-attribution-dev
Feed it some more events (copy them from segment) and have a look in the DynamoDB interface. Here is what I saw with the test event:
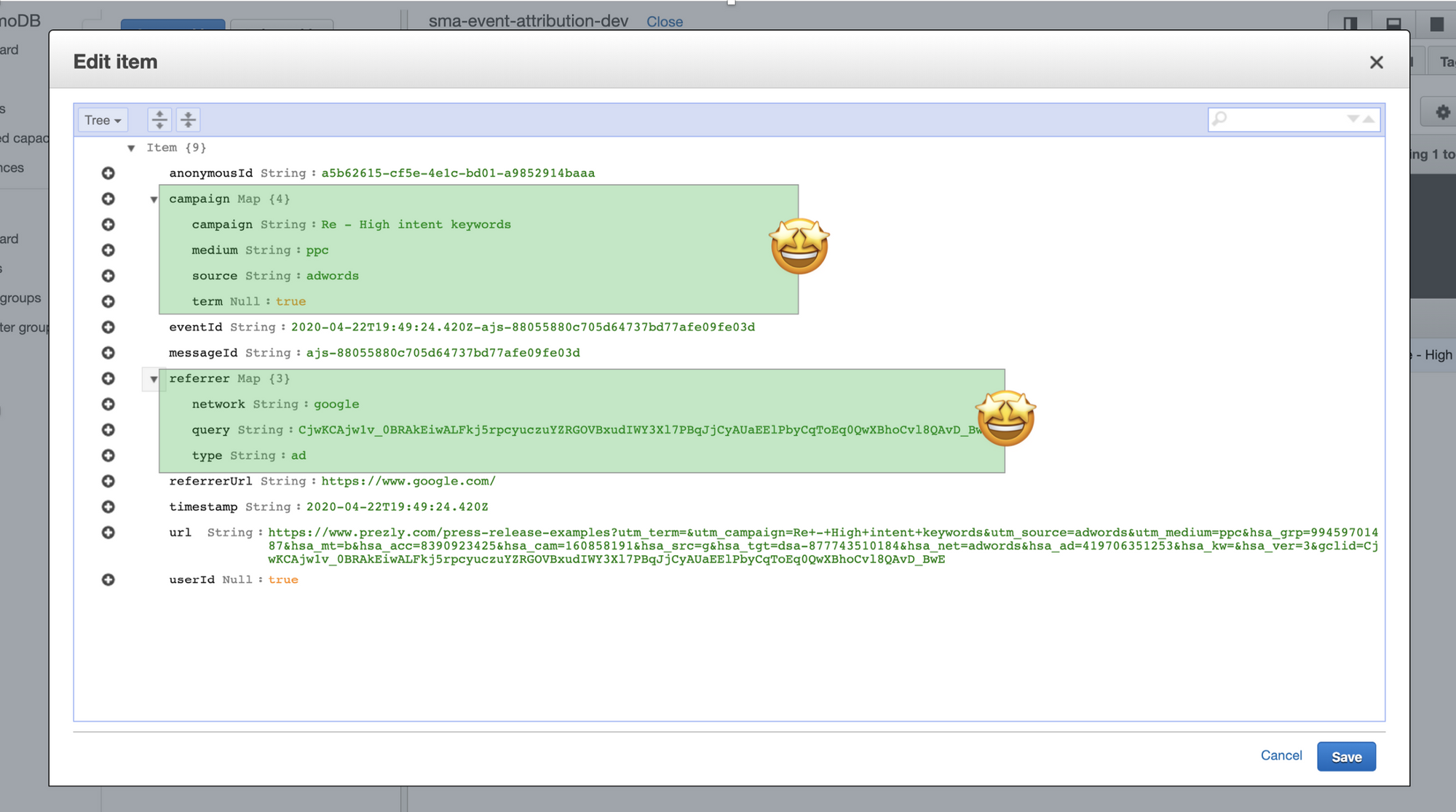
There you go. Some great progress today. Tomorrow we’ll start by moving this to production and then creating an API to generate a stream per user or anonymousId.
Other articles in the series
05/07/2021
Day 11 - Sales Attribution
03/07/2021
Day 10 - Six months later
03/06/2020
Day 9 - Dealing with tracking/ad blockers
18/05/2020
Day 8 - Feeding in sales data
06/05/2020
Day 7 - Reporting on visitor sources
01/05/2020
Day 6 - Feeding source attribution data back to Segment.com
27/04/2020
Day 5 - Feed old events
24/04/2020
Day 4 - Run in production + API
22/04/2020
Day 3 - Cleanup & Identify Visitor Source
21/04/2020
Day 2 - Capture segment events
20/04/2020
Day 1 - The Masterplan
19/04/2020
Solving marketing attribution (using segment)